
26 February 2024 ⋅ Back to blog index
string1 == string2 just works.)
string1 and string2 are equal case-insensitively, I can use lowercase(string1) == lowercase(string2), or uppercase(string1) == uppercase(string2).
uppercase() and lowercase() methods in my favorite programming language just do the right thing.
\d matches the digits 0 to 9, like [0-9].
Unicode and UTF-8 are not the same.
Unicode defines how text is represented abstractly, by assigning an integer, or “code point”, to each conceptual character. UTF-8 is a text encoding, which defines how these code points are serialized into concrete bytes so that they can be stored and exchanged on computers. There are other Unicode text encodings, such as UTF-16 and UTF-32, as well as special-purpose encodings like CESU-8 and WTF-8.
“The output file is encoded in Unicode” makes no sense in your documentation. State whether it is encoded in UTF-8 (preferably), or in a locale-defined encoding.
It is much more than that. The Unicode standard also defines how to transform the case of Unicode strings. It assigns categories to characters, such as “alphabetic” and “numeric”. It describes the so-called “bidirectional algorithm” for displaying mixed right-to-left and left-to-right text. This is only the tip of the iceberg.
Unicode contains so-called combining characters, which are not used in isolation but modify the meaning and appearance of previous characters. Examples are the acute accent “◌́”, which combines like this: “É”, and the combining overline “◌̅”, which combines like this: “x̅”. It is of course undesirable for these to be treated as separate entities by the text cursor, or for the DEL key to delete only the combining character without the preceding character. This leads to the notion of grapheme clusters, which can be considered as the “user-perceived characters”. The Unicode standard describes a relatively complex segmentation algorithm to group the characters from a string into grapheme clusters.
string1 == string2 just works.)Even though diacritical marks are available as combining characters, Unicode also includes precomposed characters for many common letter-diacritic combinations. For example, “É” and “É” look exactly the same, yet the first is one single precomposed character while the latter is the combination of the ASCII letter “E” and the combining acute accent “◌́”. To compare strings in a way that treats these at the same, they first have to be converted to a common normalization form. There are two essential normalization forms, NFC (“normalization form C”), which converts to preComposed characters, and NFD (“normalization form D”), which converts to Decomposed characters.
The two other normalization forms are NFKC and NFKD. Compared to their NFC and NFD counterparts, they do extra effort to collapse characters that are semantically very close, especially if the duplication exists for historical reasons. For instance, they convert the circled digit “①” into “1” and the precomposed ligature “ffi” (which exists for compatibility with legacy character sets) into the character sequence “ffi”.
A simple test in Python disproves this:
>>> "É".startswith("E")
False
>>> "É".startswith("E")
True
In the decomposed form, “É” actually starts with the character “E”, followed by the combining acute accent character.
Note that this is less of a problem than you might think. For example, when parsing some format, you usually scan for full words instead of advancing character-by-character.
There is no universally correct sorting for characters. A striking demonstration is the character “æ”, which in French should come between “ad” and “af”, but in Swedish should be treated like “a” for sorting purposes. Likewise, Swedish puts “Ä” and “Ö” after “Z”, but German puts them at the same position as “A” and “O”, respectively.
The order of Unicode code points is not even intended to represent a good sorting for any language. It would be difficult to conciliate this with the progressive evolution of the Unicode database since existing code points cannot be moved to make room for new ones. Code point order can be considered as completely arbitrary and works well when your code just needs some ordering, e.g., when using strings as keys in map and set data structures that are implemented with search trees. (The other case where it works well is when you are sure that the strings are ASCII, and you want to sort “a” after “Z”.)
To do linguistically correct sorting, you'll need to use the Unicode collation algorithm, which describes a way to form a sorting key for a string using given language-specific collation tailorings. The Unicode Common Locale Data Repository (CLDR), which is separate from the Unicode standard itself, contains tailorings for many languages.
Not every lowercase Unicode character has an uppercase equivalent. Some characters are even uppercased to several characters, such as the German lowercase Eszett “ß”, which is uppercased to “SS”, even though the uppercase “ẞ” does exist (it officially became valid in 2017, but remains rarely used).
In 2016, a critical security vulnerability in GitHub caused by this incorrect assumption was discovered. It was possible to get a password recovery email at an attacked-crafted address, by providing an address that was different from the account address but normalized to the same.
string1 and string2 are equal case-insensitively, I can use lowercase(string1) == lowercase(string2), or uppercase(string1) == uppercase(string2).These are not equivalent, and neither one is correct.
Continuing with the previous example of “ß”, one has lowercase("ss") != lowercase("ß") but uppercase("ss") == uppercase("ß"). Conversely, for legacy reasons (compatibility with encodings predating Unicode), there exists a Kelvin sign “K”, which is distinct from the Latin uppercase letter “K”, but also lowercases to the normal Latin lowercase letter “k”, so that uppercase("K") != uppercase("K") but lowercase("K") == lowercase("K").
The correct way is to use Unicode case folding, a form of normalization designed specifically for case-insensitive comparisons. Both casefold("ß") == casefold("ss") and casefold("K") == casefold("K") are true. Case folding usually yields the same result as lowercasing, but not always (e.g., “ß” lowercases to itself but case-folds to “ss”).
uppercase() and lowercase() methods in my favorite programming language just do the right thing.The Unicode standard only defines the default uppercasing and lowercasing for each character. Like with collation, programs can opt in to use language-specific tailorings, which adapts the case mapping to different conventions, and CLDR provides a database of language tailoring rules.
An infamous case of necessary language tailoring is the “Turkish locale bug”. English, and most other languages using the Latin script, has a pair of letters “i” and “I”, in which the lowercase has a dot but the uppercase doesn't. On the other hand, in Turkish, there is a dot-less lowercase “ı”, a dot-less uppercase “I” (the same as English), a dotted lowercase “i” (also the same as English), and a dotted uppercase “İ”. The case mapping “i ↔ I” is plain wrong in Turkish, it should be “ı ↔ I” and “i ↔ İ”.
This does not hold under any major operating system.
On UNIX (including Linux-based systems and macOS), file names are semantically sequences of bytes. It is allowed to create file with any byte sequence as the file name, even if the byte sequence is not valid UTF-8. The locale encoding normally is normally respected for file names, and it is normally UTF-8, but this is a convention only.
On Windows, the situation is a little different because file paths are semantically strings, and more precisely UTF-16 strings. However, validity is not enforced by Windows APIs. Consequently, it is possible, as on UNIX, to encounter file names that are not valid in the conventional file system encoding (in this case UTF-16).
In both cases, the situation is rare, but it exists and must be taken into account for low-level software that requires high reliability. (The WTF-8 encoding can be used if there is a need to encode potentially invalid UTF-16 into something resembling UTF-8; it is used by Rust's OsString type on Windows.)
This tenacious misconception stems from the complicated history of Unicode, of which the initial incarnations were designed for repertoire size of 216 = 65,536 characters, so that it could be encoded on two bytes per code points. However, this is no longer true since version 2.0 of the Unicode standard, released in 1996. In UTF-16, characters that do not fit in two bytes are represented on four bytes by a pair of two-byte surrogate code points.
Part of the reason some people continue to believe that UTF-16 is a fixed-width two-byte encoding, or to simply not realize the difference between characters and UTF-16 code units, is that the characters which do fit into two bytes in UTF-16, namely those from the Basic Multilingual Plane, represent the vast majority of characters in common use, even in CJK. You may be tempted to think that you don't need to support characters outside the BMP. Please don't. Although much of the other planes is devoted to rarely used characters (e.g., historical scripts like Egyptian hieroglyphs, chess symbols like “🨁”, etc.), they do include: extra CJK characters, mathematical characters (like “𝟙” and “𝔖”), and, very prominently, emojis.
Like “regular” in mathematics, the length of a Unicode string is so well-defined that it has about two dozen definitions.
For example, consider the string "🤦🏼♂️". In Rust, "🤦🏼♂️".len() gives you 17. In Swift, "🤦🏼♂️".count gives 1. In Python, len("🤦🏼♂️") gives 5 but the string in fact takes 20 bytes, and in JavaScript, "🤦🏼♂️".length gives 7 even though the string takes 14 bytes. That's right, there are at least six different reasonable notions of length. In summary:
I highly recommend Henri Sivonen's excellent article It's Not Wrong that "🤦🏼♂️".length == 7, from which this example is shamelessly copied.
Far from it. The number of code points is mostly useful in languages where strings quack like arrays of code points, such as Python, for algorithmic purposes (e.g., keeping a cursor inside a string for parsing, representing a string slice).
It is not a good measure of visual length or information density. Remember that “É” has a single code point and “É” has two. Also consider that 🤦🏼♂️ has five code points, while ﷽ has just one. Neither is it the right measure for storage size (e.g., to segment into packets, or to impose a limit); for that you should simply use the number of bytes in the storage encoding (preferably UTF-8).
If you want a quick approximation of visual length, the number of grapheme clusters, though far from perfect, is already more relevant than the number of code points. However, using it for algorithmic purposes, as is done in Swift (where strings are indexed by grapheme cluster) may prove to be a very bad idea.
The number of grapheme clusters is defined by the segmentation algorithm, which depends on character properties (such as being a combining character), and this induces a dependency on the version of the Unicode database. New versions of Unicode are released every year. This means that it is incorrect to store grapheme cluster indices in some database and retrieve them a year later with an upgraded language toolchain, as the indices might now refer to a different part of the string. Imagining how this could lead to a security exploit is left as a trivial exercise for the reader.
Even in a “fixed-width” font, not all characters have the same width. CJK ideograms take up two columns instead of one, otherwise they would be unreadable. This is reflected by the East Asian width measure. Compare:
The source for this complaint is that when compared to its UTF-16 alternative, UTF-8 uses less space for ASCII, which is the bulk of characters in Latin scripts like English, and more space for CJK characters. More precisely, ASCII characters are encoded on a single byte instead of two, and most CJK characters on three bytes instead of two.
However, it is worth remembering that a major need for a universal encoding is Web pages, and HTML code, even for pages in CJK, contains lots of ASCII because of all HTML tags. (Also, the “fairness” argument needs to be put in context since CJK languages typically use less characters for the same information density.)
For a meticulous argumentation in favor of UTF-8 as opposed to UTF-16, read UTF-8 Everywhere.
Semantically, the program interacts with the string as if it were in UTF-32, a fixed-width encoding using four bytes per character. Internally, languages often optimize the common case where the string is all ASCII, in which case ASCII can be used as a fixed-width encoding with one byte per character, or the also common case where the string is not entirely ASCII but only has characters from the BMP, in which case the UTF-16 form is effectively fixed-width with two bytes per character. Python in particular does this.
Similarly to the previous point, the language may, as an optimization, special-case strings that are entirely ASCII, or more complicated conditions. Major JavaScript engines (SpiderMonkey and V8) implement this optimization.
Go strings are UTF-8 by convention, but may contain invalid UTF-8.
Rust strings are enforced to be UTF-8. The conversion function String::from_utf8 and its cousins check UTF-8 validity, which takes time linear in the size of the string, and may fail. There is a separate String::from_utf8_unchecked function which runs in constant time, but it is unsafe to use.
Unicode grows with time. A majority of Unicode code points are reserved for future use. The space of Unicode code points is divided into 17 “planes” of 216 = 65,536 characters. As of February 2024, planes 3 and 14 are mostly unassigned, while planes 4 to 13 are fully unassigned.
The Unicode character set includes Private Use Areas (PUAs), which are entire groups, totalling 137,468 code points, that are assigned for “private use”. It can be convenient in applications to have some extra characters available for special purposes in fonts, such as for displaying icons like those from the wildly popular Font Awesome icon set. Characters reserved for private use do not have a name. Their semantics are defined by whichever application produced them.


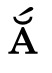

\d matches the digits 0 to 9, like [0-9].In many languages, the regular expression \d matches any character with the Unicode category Nd (“Number, Decimal digit”), which not only includes 0123456789, but also characters such as the Arabic three “٣”, the Devanāgarī six “६”, or the mathematical double-struck “𝟙”. On the other hand, [0-9] only matches the digits 0123456789.
Languages and tools with this behavior include Python, Perl, Rust, git-grep and ripgrep at least.
Unicode includes invisible characters that only have a semantic function. For example, the invisible times symbol that is in the middle of ab, which screen readers can use to read this as “a times b”.
Unicode does not attempt to define separate characters for all semantically different possible uses of a given character. Roman numerals like MMXXIV are written in the Latin script (characters dedicated to Roman numerals do exist, for compatibility with legacy encodings, but their use is discouraged). There is no curved apostrophe character; the apostrophe’s avatar is that of a curly closing ‘quote’.
When you sort strings or change their case, you need to decide on the locale. When you compare strings, you need to resist to the obvious lowercase(string1) == lowercase(string2). When you get external data, you need to refuse the temptation to guess its encoding. Programming languages with good Unicode support, like Rust, can spare you a lot of trouble with Unicode, but none so far saves you from thinking about it if you want to write correct software.
Leave a comment